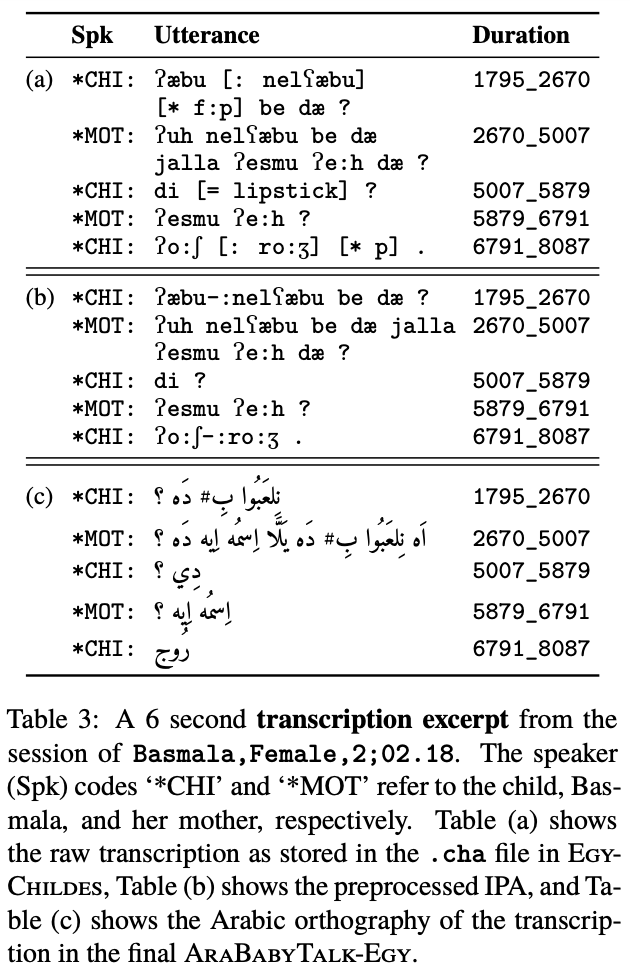
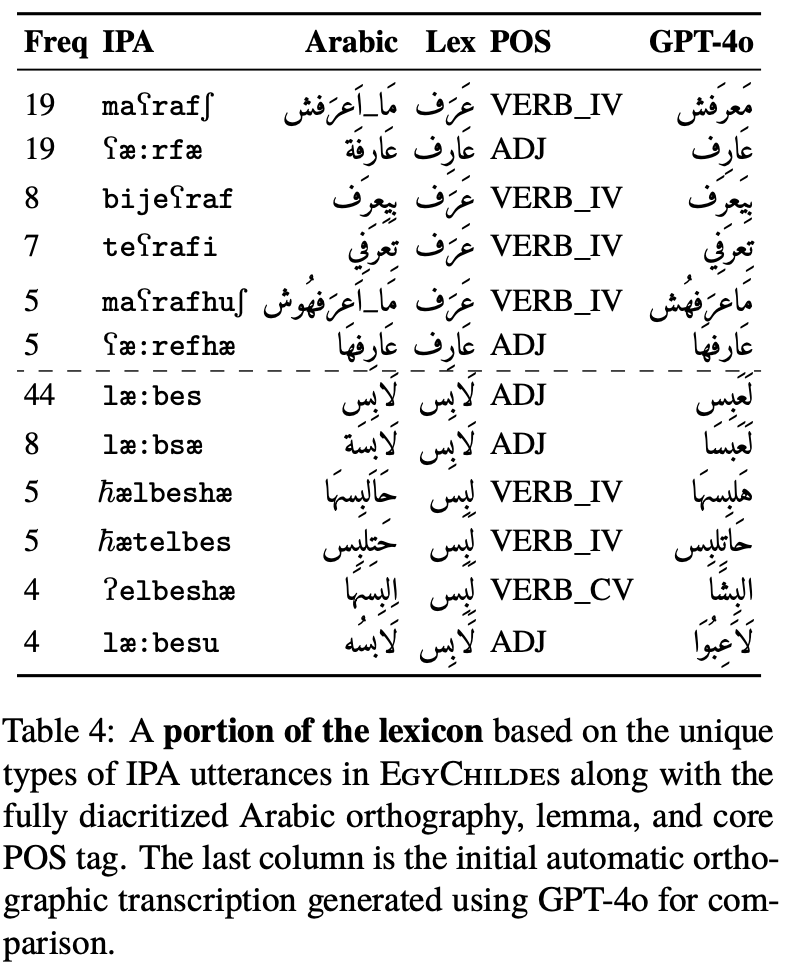
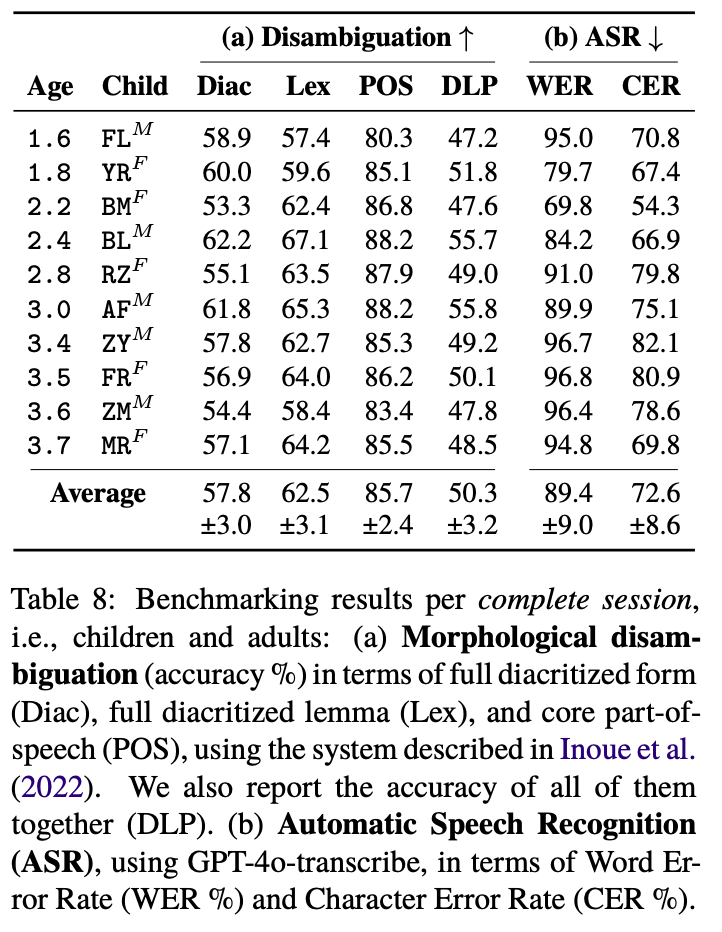
We present AraBabyTalk-Egy, an enriched release of the Egyptian Arabic CHILDES corpus, that opens the child-adult interactions genre to modern Arabic NLP research. Starting from the original CHILDES recordings and IPA transcriptions of caregiver-child sessions, we (i) map each IPA token to fully diacritized Arabic script, and (ii) add core part-of-speech tags and lemmas aligned with existing dialectal Arabic morphological resources. These layers yield ~26K annotated tokens suitable for both text- and speech-based NLP tasks. We provide a benchmark on morphological disambiguation and Arabic ASR. We outline lexical and morphosyntactic differences between AraBabyTalk-Egy and general Egyptian Arabic resources, highlighting the value of genre-specific training data for language acquisition studies and Arabic speech technology.
@inproceedings{khalifa-etal-2026-computational,
title = "Computational Benchmarks for {E}gyptian {A}rabic Child Directed Speech",
author = "Khalifa, Salam and
Qaddoumi, Abed and
Habash, Nizar and
Rambow, Owen",
editor = "Demberg, Vera and
Inui, Kentaro and
Marquez, Llu{\'i}s",
booktitle = "Proceedings of the 19th Conference of the {E}uropean Chapter of the {A}ssociation for {C}omputational {L}inguistics (Volume 1: Long Papers)",
month = mar,
year = "2026",
address = "Rabat, Morocco",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2026.eacl-long.102/",
doi = "10.18653/v1/2026.eacl-long.102",
pages = "2296--2307",
ISBN = "979-8-89176-380-7"
}
}